
Interview between Tom Kalil (opens new window), Chief Innovation Officer of Schmidt Futures (opens new window), Dr. Evan Miyazono (opens new window), Research Team Lead at Protocol Labs, and Dr. Matt Akamatsu (opens new window), Assistant Professor of Biology at the University of Washington.
Tom Kalil: I wanted to talk to Evan and Matt because of their pioneering work on discourse graphs – a potentially new way of communicating and sharing scientific arguments. I think more scientists and funders of science should be aware of these ideas. I’m also interested in the use of graphs for fostering innovation and commercialization of research, such as work by Deep Science Ventures on outcomes graphs (opens new window).
Below is a copy of the Q&A conducted over email between me, Evan, and Matt.
Individual answers are from Evan Miyazono (EM) and Matt Akamatsu (MA).
What is a discourse graph, and how are scientists beginning to use them?
EM: A discourse graph is a way of structuring and sharing scientific arguments. Each brief note is labeled as a question, claim, or evidence. These notes (nodes) are connected to each other (via edges) in a graph (opens new window) based on their relationships.
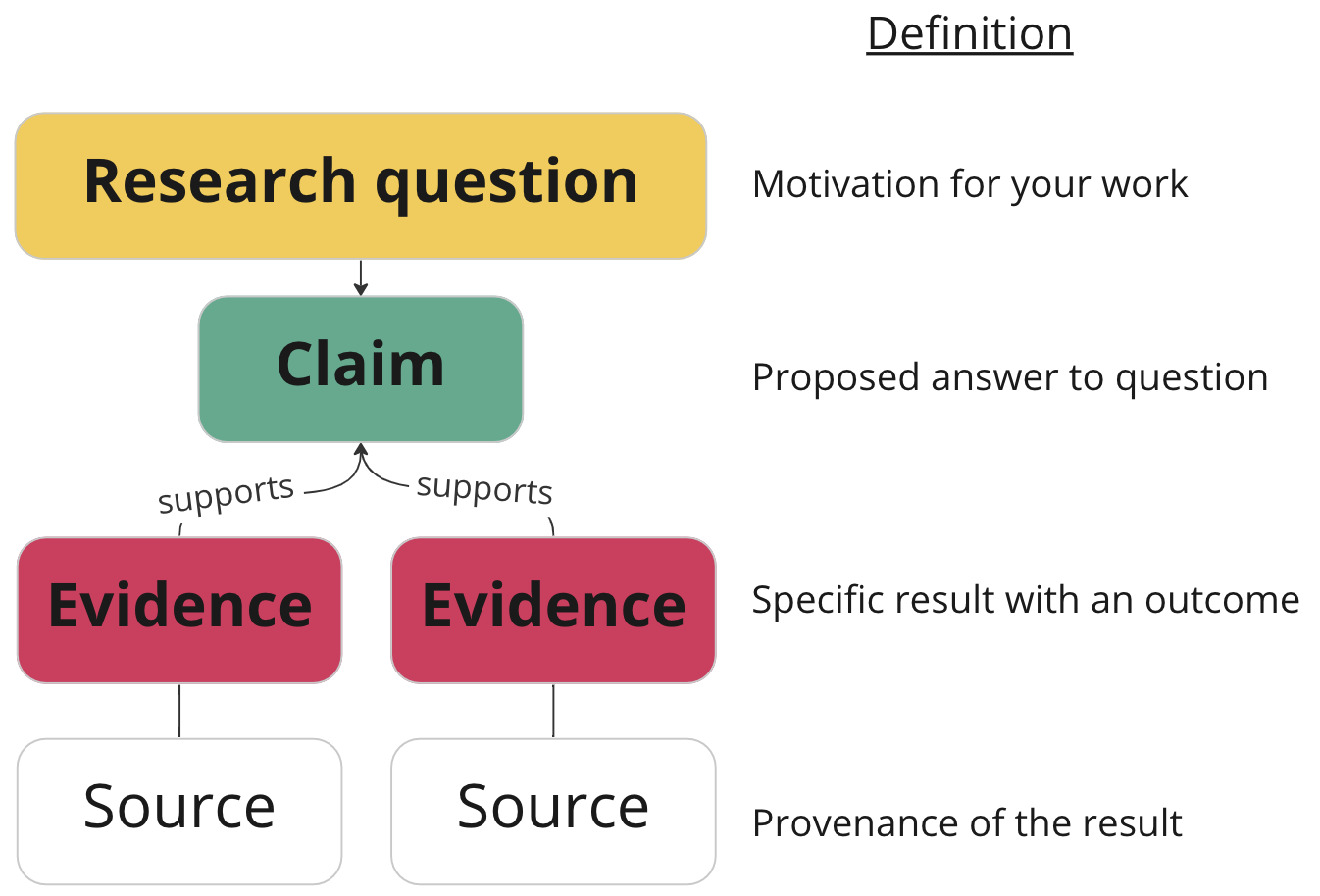
MA: Discourse graphs currently have two use cases:
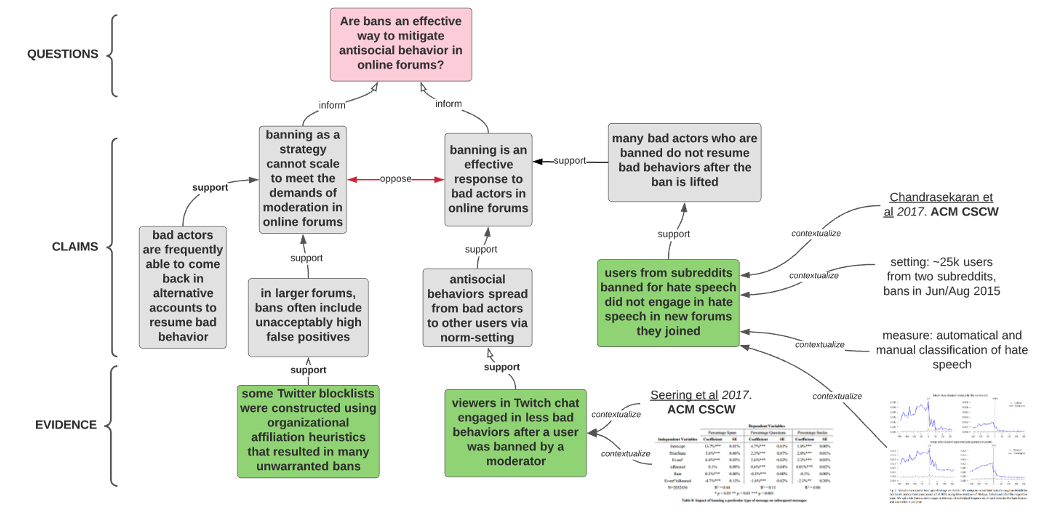
- Knowledge synthesis and sharing. A modular, reusable alternative to systematic reviews, discourse graphs capture the current lines of evidence that make up the state of knowledge in a given research subfield. Each evidence page contains enough context for the user to assess its validity and relevance, and are used to build novel claims that propose to answer a given research question. Multiple, opposing claims can coexist; since each claim is linked to the underlying evidence, each reader can assess the validity of each claim on its own merit (figure below). Discourse graphs give researchers the means to structure and reuse their literature searches, and importantly distribute the effort (opens new window) in generating and maintaining the database.
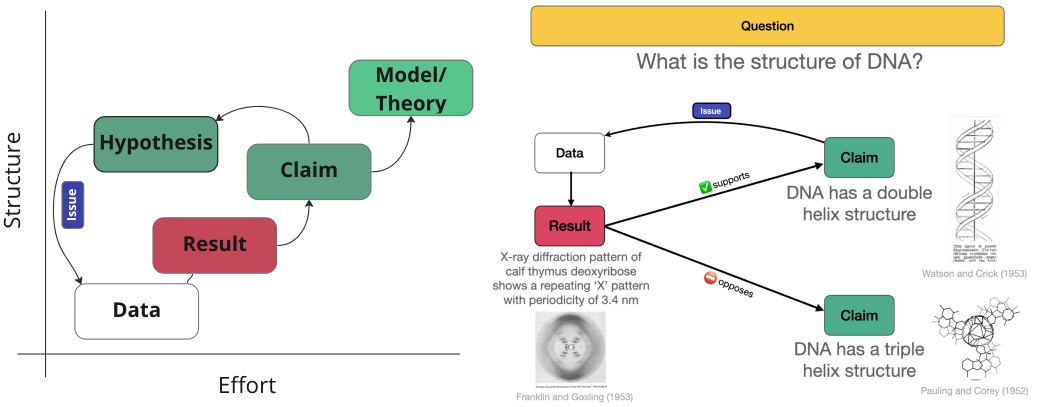
- Open-source, modular research communication. Adapting the question/claim/evidence schema to ongoing research has allowed us to discretize the scientific research process for modular, collaborative research. At the end of the literature review (above), researchers pose hypotheses (testable claims) which motivate the collection of new data, leading to original results (new evidence) that support evolving claims (figure below). Each unit of new research lives in the discourse graph for context and reuse by other researchers, potential collaborators, science communicators, and funders. This enables gap analysis and facilitates discoverability of interesting problems within the field.
MA: The Akamatsu Lab shares a discourse graph to pose new research questions, get up to speed on the current state of knowledge for that research question, and find an entry point for useful contributions. Lab members share evidence from articles, working hypotheses, requests for new experiments (called issues), and original results such that we can build on each others’ findings. Contributing to discourse graphs has accelerated students’ onboarding to our research field and given them a structured, discretized means of contributing to research.
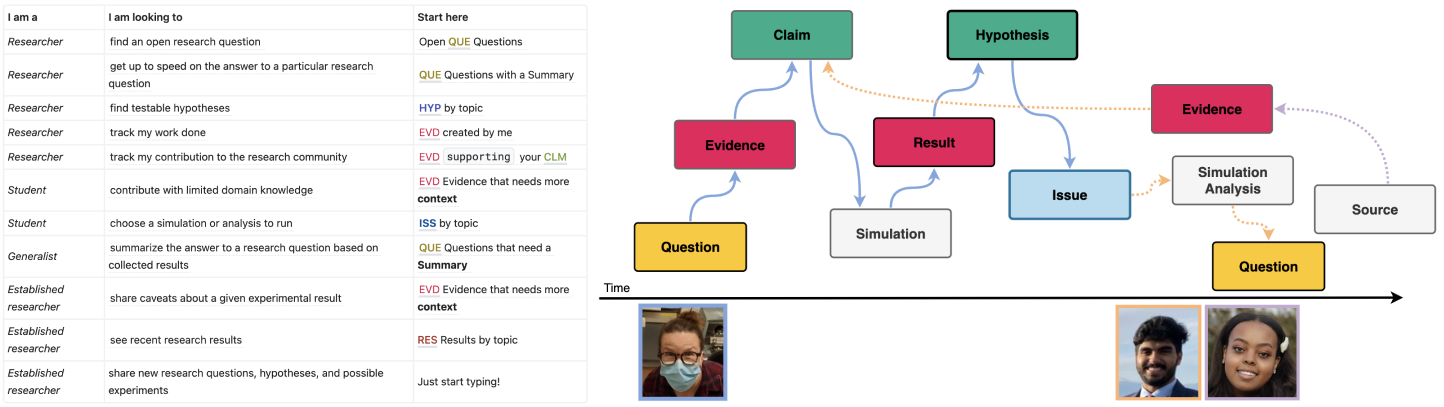
Researchers are generating and sharing[1] their discourse graphs (most with permissioned write, permissionless read access).
How did you get interested in discourse graphs?
EM: My team had invited Prof. Joel Chan to present his research on synthesis of academic literature. He started describing how he’s changed the way he structured his notes based on his research, and when he said “I don’t give new students a stack of papers when they join my lab, I give them access to my notes graph” I formed the immediate conviction that this was the future of scientific collaboration. It was easy to see this as a tool to achieve the paradigm of collaboration presented in Michael Nielsen’s Reinventing Discovery.
MA: Our project is based on the hypothesis that new tools for collaboration can facilitate cultural and organizational change within scientific research communities. I connected with Joel Chan after trying networked note-taking tools to connect my notes for a collaborative project on SARS-CoV-2 cell biology during the pandemic. Our conversations led to the insight that discourse graphs could be applied to our ongoing research, which might facilitate the types of modular, rapid research contributions that I wished were possible for the COVID researcher community.
What do you think are the potential advantages of discourse graphs, relative to the journal article or preprint?
EM: A journal article is usually the culmination of 6-24 months of work. The initial idea or result, which would be usable to others in the field, often is generated in the initial months of the project. The promise of Discourse Graphs (or any robust, graph-based, notes schema) is that useful progress can be shared sooner, with sufficient context for collaborators or with the research community at large. Preprints increase the accessibility, but usually do not increase the availability of research to the extent that it could be said to accelerate science[2].
DGs provide the opportunity for modular peer review, with clear affordances to ask “does this evidence really support that claim?” or “is this evidence reproducible?” without needing to pass judgment on an entire body of work.
Journal articles and preprints are also required to demonstrate a complete scientific narrative, starting from a research question, generating a hypothesis, designing and running an experiment to test the hypothesis, and generating conclusions. Researchers must perform all steps to receive credit; discourse graphs could enable specialization of labor within the scientific system. While the complete narrative still has clear value, discourse & results graphs enable us to reward efforts both in whole and in part[3]. Eventually, discourse graphs could also make scientific data more computable (discussed more in later questions).
MA: In my field, journal articles have ballooned to include dozens of results and authors, taking several years from idea to publication. Collaboration is disincentivized because a single first author claims the majority of credit. Individual researchers collect individual results - why not attribute credit for each research contribution? Generating a discourse graph cites atomic units of work -- a single result or hypothesis -- so that researchers have an ongoing, accurate representation of their work and its impact. Journals’ “author contributions” sections have provided limited value because they are added manually post facto and do not track individual results or intellectual contributions.
While journal articles and preprints center around one or more claims, discourse graphs link to the underlying evidence, which makes it easier for other researchers to make their own claims from the aggregated evidence.
Journal articles tend to select submissions based on perceived novelty of claims, rather than rigor of results. With discourse graphs, we envision that results from a single experiment will gain strength over time by being reproduced by other researchers. Overlapping work will be mutually beneficial rather than adversarial. Hypotheses can be updated as new evidence becomes available. Research output, rather than resembling single-use consumables, will instead be reused in a sustainable scientific ecosystem. These global changes result from the following local changes:
Modular peer review – individual hypotheses can be challenged by others who present additional evidence from the literature or their lab notebooks. Peers can corroborate results by reproducing or flagging for irreproducibility, supporting constructive addition to the work rather than gatekeeping.
Decentralized coordination – within groups, the transparency facilitates useful exchange of research between peers, rather than relying on PIs as the primary sources of plans and ideas. This decentralization raises the agency and responsibility of individual researchers, and facilitates the generation of novel organizational structures for science (e.g. DAOs).
Constraints liberate – an open, structured conversation between researchers from idea to hypothesis to result to claim more closely reflects the intrinsic discovery process (have an idea, get excited about it, share with people who want to help figure out the answer, figure it out together and celebrate the finding) than the current first-author incentive system (have an idea, guard it, toil alone for years in order to claim sole credit for contributing but a piece to a broader collective endeavor).
What do you view as the primary obstacles to the adoption of discourse graphs, such as the incentives for scientists to contribute?
EM: One obstacle for researchers is becoming comfortable sharing results and ideas sooner[4]. Hopefully the sharing of progress immediately and continuously is viewed as an extension of the preprint revolution, rather than a new practice. We need the community to respect notes graphs as artifacts in the scientific literature, which means integrating them into existing workflows and allocating credit (i.e. funding, awards, patents, & citations) based on work done in notes graphs. The current culture in many fields is one of secrecy over openness, which needs to be inverted. This secrecy seems to be driven by zero-sum reputation building, rather than focus on cooperative achievement of shared goals.
MA: Academic career incentives are an obstacle to adoption. DGs encourage researchers to make careful contributions that can be built upon, which may not correlate with current “first past the post” publication incentives. In DGs, impact is assessed by the usage and lasting power of individual results, rather than by article citations or journal reputation[5].
Many academic researchers (particularly established researchers) will resist moving away from journal articles as career currency. That said, I imagine that DGs and journal articles can coexist for the foreseeable future; in our lab, we will publish some traditional journal articles and co-publish companion DGs, or alternately micropublish individual results or conclusions from our DG as connected modular preprint articles[6].
EM: Journals currently provide a valuable signal around recognizing certain research as important and making the results salient, and researchers will need new habits and tools to do this at least as well in a world where all science ideas are shared immediately and continuously; therefore, we need to smoothly transition to such a world, still leveraging existing incentives and metrics, like citations and publications. The eventual use of tools leveraging NLP over DGs to filter the most relevant contributions and then match and merge relevant results clearly has capacity to surpass the information salience provided by journals.
Another obstacle is adopting the subtle change in how they take notes[7]. This should be close to the change of using Overleaf or Google Docs instead of emailing .doc attachments to each other, but it is a barrier. There are multiple emerging proof-of-concept tools for generating DGs, like Lateral.io (opens new window), Samepage.network (opens new window), and tooling for RoamResearch (opens new window); however, the user experience for teams is still early days and a bit rough around the edges.
Lastly, DGs do not carry universal context. Much of any single working DG will initially only have enough context for close collaborators to use it. That said, the addition of this context is often much of the beneficial aspects of writing up research results in journals, so we see this as an epistemological limitation on scientific communication made explicit by the graph format, rather than a limit of the format itself. Relatedly, DGs are most useful when they are extensions of a researcher’s (or group’s) ongoing efforts at notetaking and sensemaking; in this way the DG is not an external additional layer of formalization to spend time on, but instead serves as an integral tool for shaping and improving the thinking process, from unstructured to structured thought and communication.
What role could different types of individuals and organizations play in accelerating the adoption of discourse graphs?
EM: Funders could give funding for research contingent on open publishing of structured notes for that research, in support of open science and positive-sum collaborations. However, the idea becomes more compelling if it’s recognized that funders may eventually be more interested in the discourse graph as a research output. These discourse graphs could be used to inform future funding allocation decisions (e.g. pursuing a specific question raised or searching for additional evidence to back a claim). I expect that some research funders and teams will realize a competitive advantage by using research roadmaps (an extension of the discourse graph schema that we’re developing to describe yet-to-be-completed research) to guide their research plans, expectations, timelines, and decisions.
MA: Funders could accept structured hypotheses within discourse graphs as substitutes for grant proposals. Funders can also support developers who are making discourse graph tools easier to use, and allow teams to hire “cybrarians” (knowledge graph enthusiasts who assist in generating and maintaining a team’s DG). It might be fruitful to found an organization focused on improving discourse graph tools for teams. Similarly, assembling/funding new teams or organizations and giving them an empty discourse graph (and research assistant) would give teams the chance to assemble a discourse graph together from scratch.
EM: Publishers could partner in the development and usage of citation conventions and infrastructure to be applied to discourse graphs[8]; longer term, publishers could co-publish discourse graphs alongside or embedded within journal articles, and update their citation metrics to leverage the added value of discourse graphs. Publishers could also create high-profile venues exclusively for work shared in an immediately and continuously open way. In this way, examining the discourse graphs behind the science could also reduce the review burden as we move into an age where large language models dramatically accelerate the rate at which researchers can write manuscripts or reformat them for resubmission.
MA: Researchers could pilot the use of team discourse graphs that are open or will be shared upon publication of resultant journal articles and results. They can provide user feedback to the developers improving the usability of discourse graph tools.
EM: Developers could build tooling for interoperability between different note-taking platforms to facilitate adoption; build tools to use discourse graphs to assist in knowledge synthesis, possibly converting parts of the existing scientific literature corpus into discourse graphs, or using discourse graphs as logical back-ends or training data for NLP & LLMs).
What types of pilots should the research community try? How might we evaluate the efficacy of these pilots?
EM: A structured program could be developed for any of the above roles. Examples could include:
- A funder funds research collaborations that pilot discourse graphs for coordination & synthesis; the individual teams pilot discourse graph use internally to measure if it noticeably results in more cross-pollination of research elements
- A funder, professional organization, or institution makes a publication community (e.g. PubPub (opens new window)) and, invites teams of researchers; this could be tied to funding opportunities
These pilots should seek to show that discourse graphs are both (a) appealing to use and (b) more effective than other methods of collaboration. The following are a few ideas of how these could be measured (not intended to be either exhaustive or particularly robust):
(a) Test the claim: “Discourse graphs are appealing to use” with
- net promoter scores, or other reviews
- daily or weekly active users
- referrals (fraction of users joining on a collaborator’s recommendation)
- number of new nodes per public graph
- number of public graphs
- number of collaborators per graph
b) Test the claim: “Discourse graphs are more effective than other methods of collaboration” with
- citations per discourse graph node vs. final paper (and relative time lag)
- subjective evaluation of the rate of progress in subfields where shared notes graphs are used vs. other fields
How do discourse graphs relate to NSF’s support for knowledge networks, such as the Convergence Accelerator on Open Knowledge Networks (opens new window), which has funded projects like the UCSF-led Biomedical Open Knowledge Network (opens new window)?
EM: Knowledge networks provide unifying venues for data; discourse graphs represent the scientific process and its epistemological uncertainty in the format of a graph.
In this way, we should expect discourse graphs to leverage and, in some ways, extend knowledge networks.
I envision the difference as follows: a paper tomorrow might analyze and draw new insights and conclusions from a knowledge network. These insights and conclusions would be structured as a discourse graph, in such a way that a future LLM might be able to generate a research paper from the discourse graph.
Discourse graphs can identify points of contention within nodes of the knowledge graph, and propose hypotheses that explain some of the contents of the domain-specific knowledge graphs. Most likely the DGs will have simpler and more universal ontology, applicable to most empirical research, while knowledge graphs will have boutique and evolving ontology that is unique to each field or subfield.
What role can large language models play in automating the process of building discourse graphs, and how can the availability of discourse graphs increase the performance of large language models for tasks such as question-answering?
MA: We and others are making early progress using user-annotated papers as training data to help GPT-3 classify discourse graph elements of research papers. In this way, discourse graphs will help LLMs to extract relationships between claims from the existing academic literature (opens new window). LLMs can also summarize the context for a given piece of evidence and tie a sequence of discourse nodes into a narrative, to help translate between discourse graph content and traditional articles for diverse audiences. As a medium-term aspiration, an LLM could generate new research questions or hypotheses from existing discourse graphs by identifying unseen patterns. Eventually these language models would be able to reason over the claims and evidence in the graph.
EM: Discourse graphs should also be able to provide a source of truth to prevent hallucinations of scientific LLMs. Within my team, we claim that discourse graphs could be effective in reducing hallucinations by LLMs because they leverage LLMs' focus on syntax in a clever way to impart semantic meaning that humans can later extract.
If you’d like to support the improvement or adoption of discourse graphs in any way - you can reach Evan, Matt, and other members of the Discourse Graph community by emailing discoursegraphs@protocol.ai
Claims are made with implicit reference to some context. MA: so far, we've found that our discourse graphs provide sufficient context within teams or groups of collaborators, but we'll need to prepare a subset of the pages so that there will be enough context for a wider community. ↩︎
Peer review has been shown to 1) not filter out false results (shown by the replication crisis), and2) not be strictly necessary for credit & rigor (preprints + eLife change (opens new window)) ↩︎
EM: I have anecdotal evidence that some materials science researchers who generate the highest quality reagents/devices may struggle to get publications because they specialize in synthesis/fabrication, but they’re never listed first on their collaborator’s high-profile publications. Additionally, NASA’s policy change to immediately open data from JWEST (opens new window) has been met with justifiable push-back by researchers who propose the data collection, because their significant value may go unrewarded in the current paradigm of crediting publications. ↩︎
MA: an intermediate option (which we are using) is to share results within your trusted network (e.g. lab) until it is ready to be shared more widely. ↩︎
MA: I am advocating for impact to be assessed using a qualitative contributor page, reminiscent of the “github contributor (opens new window)” page, that displays which subsequent hypotheses and results rely on your research contributions. Rather than replacing journal impact factor with another metric that people will over-optimize for, such a contributor page could serve as a robust, accurate, and interactive 5-minute (but not 5-second) assessment of a researcher’s impact in their field. ↩︎
EM: I am interested in a more incremental approach, wherein we start applying existing metrics to both discourse graphs and scientific journals in the near future. Eventually, I’d like to see journals acting primarily as a system to highlight impactful work being shared in discourse graphs, with most journal papers acting the way that review articles, survey papers, SoK papers, and metastudies do in their respective fields, and at this point, it’s likely possible to host many different quantitative and qualitative automated metrics that tenure committees or funders could use to estimate individual researchers’ potential or impact for a specific problem. ↩︎
MA: Knowledge workers I know have tended to benefit immediately from switching to graph-based note taking; it has taken 1-2 weeks for people in my lab to adjust (and we are all sharing one graph!) ↩︎
EM: It’s worth noting that peer-reviewed publications have a reputation system to reduce gaming the citation metrics by only counting citations from certain venues, and discourse graphs might naively be susceptible to this gaming. Existing metrics like h-index, however, could make a useful distinction between (1) discourse graph nodes directly cited by papers in approved publications, (2) discourse graph nodes transitively cited by such papers, and (3) discourse graph nodes that do not have a citation connection to such papers. I claim that counting only nodes in (1) and possibly also (2) would prevent this form of gaming. ↩︎